

Data Lakes: What Are They and How Do They Work?

Data lakes. If you think this concept seems nebulous and trendy, you’re not alone. Data lakes are a relatively new concept that are in the midst of earning their popularity and laurels across industries.
Despite their newness, data lakes are not to be taken lightly. Data lakes are changing the way organizations leverage data to drive unprecedented business value by overcoming limitations of preceding technologies like data warehouses.
In fact, an Aberdeen survey saw organizations adopting data lakes for four main reasons:
To increase operational efficiency.
To make data available from departmental silos, mainframe, and legacy systems.
To lower transactional costs.
To offload capacity from mainframe/data warehouse.
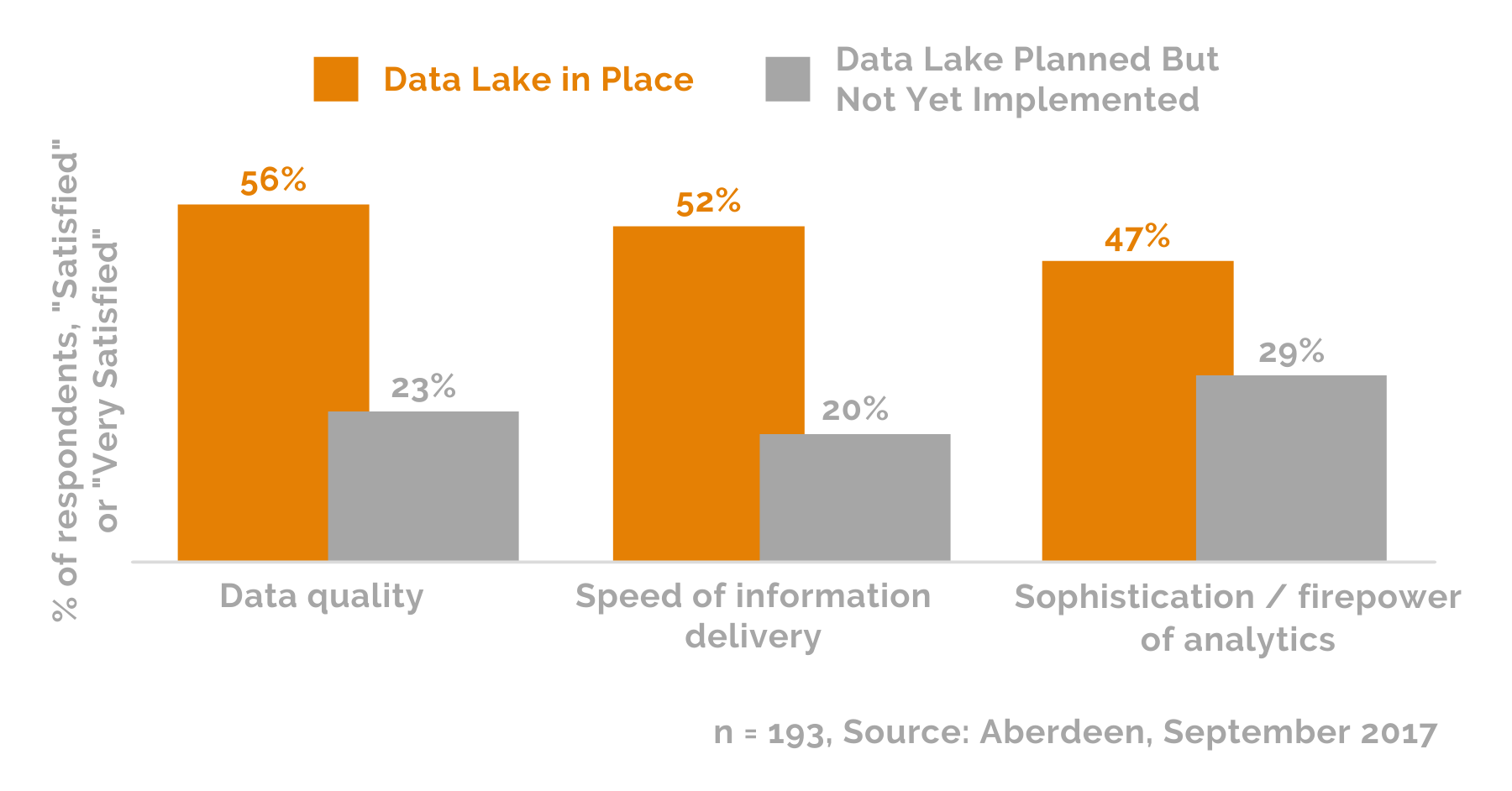
According to this same survey, enterprises with data lakes in place reported significantly higher satisfaction with (1) data quality, (2) speed of information delivery (3) sophistication/firepower of analytics compared to organizations with alternative data solutions in place.
In this piece, we’ll introduce you to the evolving concept of data lakes including what they are, why they matter, and a framework for how they can be applied in business.
Let’s get started.
What Is a Data Lake?
A data lake is exactly as its name would suggest: a collection of data in a localized area with different sources feeding into it. Think about a typical lake. Now, imagine a waterfall feeding into it on one side, a stream feeding into it from the other side, and several little creeks scattered along the shoreline.
In terms of a data lake, imagine the water is made of data, coming from various sources. Say the waterfall represents data originating from a human resource management (HRM) system, while the stream is data flowing from your customer relationship management (CRM) software. This would mean the lake itself is a collection of data from your HRM and CRM sources.
It’s common for organizations to operate using optimized tools for specific purposes, and this strategy often extends to software use. That is, it’s typical for an organization to use purpose-built software to optimize their organizational efficiencies. This may mean that a single organization uses a specialized software for marketing purposes, a specific software for human resource management, a separate system in the warehouse for inventory management, and another program optimized for financial tracking and reporting.
This is a simplified example, as it is likely that a typical organization would have many more facets tapping into the benefits offered by the numerous software packages available on the market. For example, finance is often an area where we see multiple software applications being used for financial tracking, reporting, and auditing purposes.

The Challenge with Fit-For-Purpose Software Use
One major issue with structuring software utilization this way is that software packages don’t have a standardized formatting structure and, therefore, are seldom able to communicate with each other. This results in an inability to combine datasets from various software platforms and creates great difficulty when trying to derive insights across multiple processes, an extremely valuable function for operational excellence initiatives.
For example, within a manufacturing environment it might be valuable to be able to track a project from proposal to delivery. This may include details surrounding the bid and proposal process, items used to manufacture the components that make up the project, and billable hours accumulated throughout the process.
In most environments, tracking a project from proposal to delivery involves tracking the project across several disjoint systems, thus requiring that relationships be created between the different systems before meaningful cross-system analysis can be performed.
Use Case: Data Lakes for Parent Companies
From a financial perspective, it’s useful for parent companies to be able to track reporting, conduct analysis, and view performance across some or all the companies in their portfolio. When these companies use different accounting and finance systems, the parent company is faced with the challenge of relating these systems before being able to derive useful insights. Furthermore, larger manufacturing companies often own and operate multiple sites. While these parent companies may have their interest invested in a single market sector, it is often the case that even within the same market sector different sites will operate using completely different software configurations.
Use Case: Data Lakes for Large Enterprises
An organization that aims to leverage big data to inform decisions and optimize business processes might consider implementing a data lake to collect enterprise-wide data. Not only does a data lake store raw data in their native form, but the data streams that feed into the lake also have unique and highly advantageous features.
Some of these features include transporting huge volumes of data, potentially data that is dynamically changing, and doing so in a rapid fashion (often in real-time). To reap the benefits of the data lake structure, there are important prerequisites that big data should meet. Data entering a data lake via a data stream should be accurate, current, and from a trusted source. Moreover, the data should be comprehensive, aim at a purpose, and be relevant to the organization using it.

Data Lakes vs Data Warehouses
Structured vs Unstructured Data
It’s easy to see how issues resulting from the lack of a standardized formatting structure and subsequent challenges to cross-system communication can compound into significant issues for an organization.
One method to circumvent the lack of standardized data formatting is to use a data lake to combine all data into one giant pool of data. Data lakes can take on all data enterprise-wide, regardless of the structure of the data, and store it as raw data for further exploration. Unlike data warehouses, which require standardized structured data to enter the system, data lakes allow for data to enter in their native formats.
In the data lake, it’s up to the end-user to structure the data and create relationships when data is extracted, saving the upfront cost of transforming data on its way into storage. Due to the lake’s ability to store unstructured, structured, and semi-structured data all the same, it’s vital that the data lake is governed by strict policies to prevent it from becoming a swamp.
Data Analytics vs Data Science
A key difference between data lakes and their predecessor, data warehouses, lies in the types of activities each of these data storage solutions are best fit for. With data warehouses, where incoming data are structured according to a predetermined and standardized system, data is often used for batch reporting, business intelligence, and visualizations.
With data lakes, where incoming data are not structured, applications can be broader and more sophisticated, making activities like machine learning and predictive analytics a reality for organizations.
Processes Surrounding Data Lakes
The process surrounding data lake operations is typically described within four key elements: data ingestion, storage, application, and governance.
1. Data Ingestion
Data ingestion refers to the process of populating the data lake using the various data pipelines that exist within an organization, that is, the different software systems used throughout the enterprise. Since data lakes store data in their native format, the lake’s data ingestion process does not require transformations and is therefore highly efficient.
2. Data Storage
The next stage, storage, is the “lake” itself. Within the lake, many different processes can take place. Often, these processes include organizational activities such as preparing data, capitalizing on features that exist within the data, and initializing machine learning activities.
3. Data Application
From here, data can be applied to generate useful insights, whether through dashboards or applications, and can even be useful for automation purposes.
4. Data Governance
Finally, governance is an essential component to a successful data lake as it defends an organization’s lake from “polluted” or “dirty” data. Without governance, the data lake would turn into a data swamp and potentially expose the organization to data quality, security, regulatory, and compliance vulnerabilities.
Data governance should include a method for unifying the data meaningfully. A data catalog is often used in conjunction with strict data governance policies to aid in unifying the data by systematically tagging the data. When data lakes are created mindfully, they contain a wealth of useful information representative of the entire sum of knowledge available to an organization.

Data Lakes in Action: The NFL’s Seattle Seahawks Dive Deep
In 2019, the NFL’s Seattle Seahawks partnered with Amazon Web Services (AWS) to provide cloud, machine learning, and artificial intelligence services to the Seahawks enterprise. AWS worked with the Seahawks to build their very own data lake in hopes of improving player safety and performance on the field. The Seahawks’ objectives for the data lake appear to be focused on three key areas: talent evaluation and acquisition, player health and recovery times, and game planning.
As with many data- and tech-related innovations, the best approach for your organization to take when it comes to data – from data storage solutions to best practices surrounding data and governance – will depend greatly on the needs and context of your organization. If you have questions about what solution is right for you, or if you would like to see more content on any of the subtopics mentioned within this article – please reach out to our team at hello@lunikoconsulting.com.